Cup of Machine Learning From Starbucks
have tried before to ask waiter at Starbucks if he could able give you a Cup of KNeighborsClassifier , RandomForestClassifier and DecisionTreeClassifier , I know that seemed very strange but that what actually Starbucks doing to predict many about its customer
in this article i will try to go through as data scientist at Starbucks Kitchen Machine Coffee and assign you as Data scientist Presta.

project over view :
this datasets contain simulated data about customer behavior on the rewards from mobile app , company used to send offers via app to customers and this offers varied from bogo “buy one get one free” to informational and discount , but not all customer who received offers interact with it or open it , so we need to explore validation of offers and customer interacting with it
Problem statement
we need to predict purchasing offers to most response customer (offer _received , offer viewed , offer complete ) based on demographic attributes of customer and other attributes of company offers by applying some sort of unsupervised machine learning (KNeighborsClassifier , RandomForestClassifier and DecisionTreeClassifier) but before applying model , datasets need to clean and asses then making some data exploratory to know some information about our customer and offers effectiveness also trying to answer following question
What the distribution of income with age_range ?
what is distribution of Customer age range?
What is the age distribution across gender with income ?
using of f1 score to check accuracy of our models and we can choose one to use .
Project Metrics
I will use accuracy and F-score metrics for comparison and to test out the performance of the models.
according to score of F1 for test and train for 3 clustering we user we judge the and choose which model will be the best
F1 Score is needed when you want to seek a balance between Precision and Recall. Right…so what is the difference between F1 Score and Accuracy then? We have previously seen that accuracy can be largely contributed by a large number of True Negatives which in most business circumstances, we do not focus on much whereas False Negative and False Positive usually has business costs (tangible & intangible) thus F1 Score might be a better measure to use if we need to seek a balance between Precision and Recall AND there is an uneven class distribution (large number of Actual Negatives).
https://towardsdatascience.com/accuracy-precision-recall-or-f1-331fb37c5cb9

Data cleaning and Implantation :
we have three datasets “portfolio.json , profile.json, transcript.json” all this three datasets include all information regards to customer it and offers awarded to customer and portfolio
data cleaning : Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset.
Cleaning up of this portfolio datasets
1- changing the name of id to offer_id as we need to make it as primamry key and we will use use it to join other dataset.
2- making a one hot encoded with channel and separate every channel .
3- making one hot encoding to offer_type and drop offer type.
Cleaning up of this profile dataset :
1- removing outlier from age .
2- change “became_member_on” datatype to be datetime .
3- changing column id to customer_id .
4- check null information and drop column with null .
5- create age_range from age
6- create days_as_member from become a member.
Cleaning up of this transcript dataset :
1- change a person to Customer_id .
2- change value to be “offer id “ and remove str before it .
3- make one hot code for event value.
4- change time to days.
some Analysis outcomes
Customer age statistics as follow
count 14825.000000
mean 54.393524
std 17.383705
min 18.000000
25% 42.000000
50% 55.000000
75% 66.000000
max 101.000000Customer Income as follow
count 14825.000000
mean 65404.991568
std 21598.299410
min 30000.000000
25% 49000.000000
50% 64000.000000
75% 80000.000000
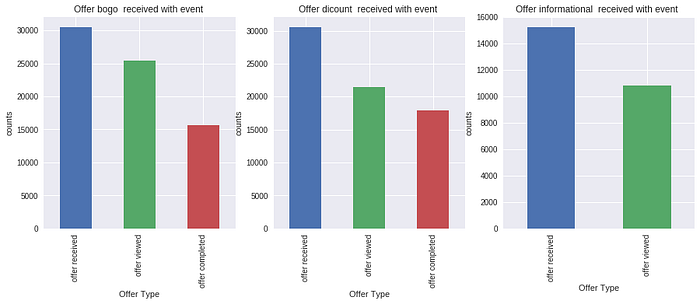
max 120000.000000events counts per each customer
transaction 138953
offer received 76277
offer viewed 57725
offer completed 33579the following graph show occurrence of each event response from customer to event type
Data Exploration & Data Visualization
Trying to generate question and its answer from data point of view
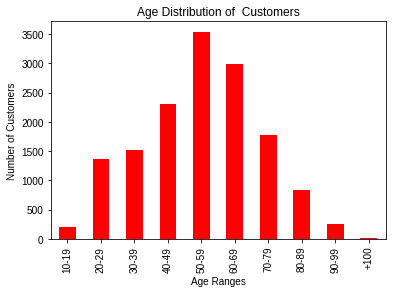
1- what is distribution of Customer age range?
customer age take the bell curve for the age range what is called normal distribution mean = median = mode.
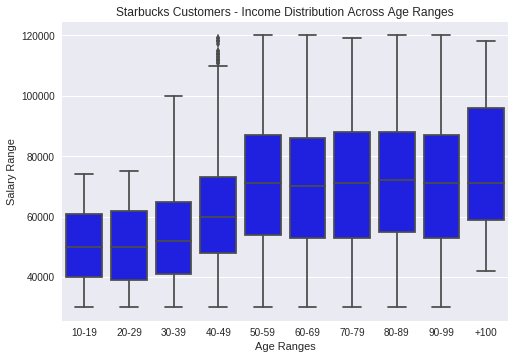
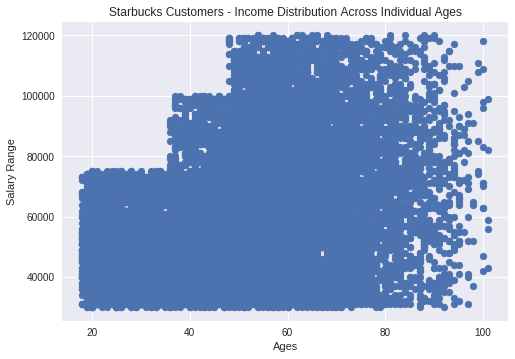
What the distribution of income with age_range ?
it shows that : for young age range income is low and range of income not height and thus understood , also income increase by age_range increase also range of income increase until reach to the age range more than 100 years old
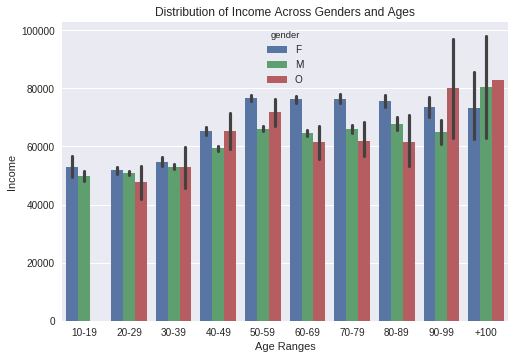
What is the age distribution across gender with income ?
we found male is higher at all ranges excepted ranges after 80 years old and second plot shows all income vs age range by consider gender it show higher income for mid age range for female and other is male
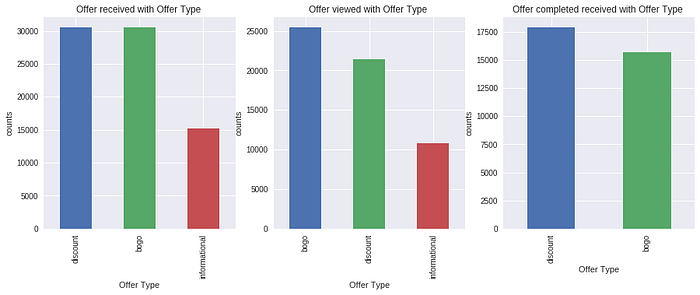
How many offer type per each offer status ?
it is appears that discount is the highest offer type all time
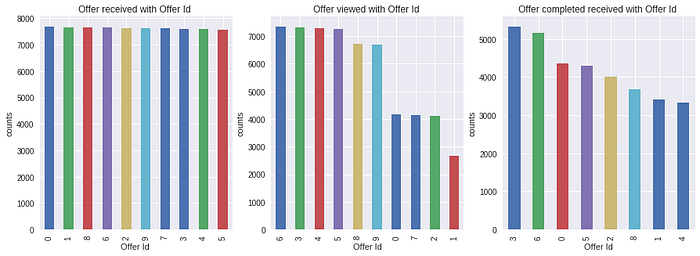
also offer_id for all offer type and it count
Data Prepossessing and model Implementation
using classification to detect event (offer received , offer viewed , offer completed) , so first we need to prepare data to apply model
1- making merge of all datasets we have in one and clean it again .
2- normalizing data with MinMax scaler .
3- divide data to label and feature .
4- splitting data to train and test for y and X.
5- using 3 type of classifier (KNeighborsClassifier , RandomForestClassifier and DecisionTreeClassifier) and i have used a test size as 0.4 and train size as 0.6 as follow and random states change from 0 to 42 and tried the effect of that on our model but i haven’t realized high differences
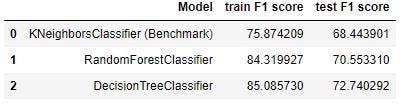
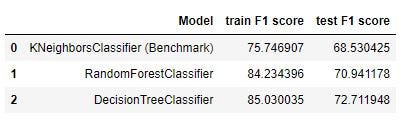
some of difficulties i have meet to working with null values i have forward fill income for missing data and dropped some of the other data i think will not affect on the model
models difference
Decision trees are very easy as compared to the random forest. A decision tree combines some decisions, whereas a random forest combines several decision trees. Thus, it is a long process, yet slow.
Whereas, a decision tree is fast and operates easily on large data sets, especially the linear one. The random forest model needs rigorous training. When you are trying to put up a project, you might need more than one model. Thus, a large number of random forests, more the time.
the F-beta score.
The F-beta score is the weighted harmonic mean of precision and recall, reaching its optimal value at 1 and its worst value at 0.
The beta parameter determines the weight of recall in the combined score
refinement :
trying to bring more balance data to the model which will achieve in get model to real case , i think data cleaning and sharing all features by correct weights will make the model more powerful and real
cross validation done to Evaluate machine learning models on a limited data sample. That cross validation is a procedure used to avoid over fitting and estimate the skill of the model on new data as we can see the scores of cross validation for DecisionTreeClassifier is the best
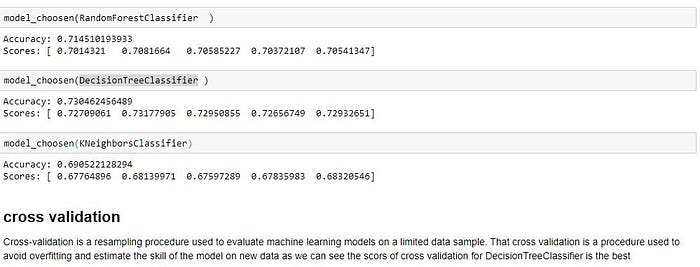
Model Evaluation and Validation
we have evaluate the model by using F1 score for training and testing and according to the highest number of this test we can judge about the suitability of this model
justification
The validation set (test data set) is used to evaluate the model. Both the models are better than the benchmark. The best score is created by the DecisionTreeClassifier model, as its validate F1 score is 85.10, which is much higher than the benchmark. The RandomForestClassifier model scores good as well compared to the benchmark, with a test F1 score of 75.87 . Our problem to solve is not that sensitive which requires very high F1 score, so the scores are good & sufficient and can be used for the classification purpose to predict whether a customer will respond to an offer. Reflection
Reflection
What is the age distribution across gender with income ?
we found male is higher at all ranges excepted ranges after 80 years old and second plot shows all income vs age range by consider gender it show higher income for mid age range for female and other is male
What the distribution of income with age_range ?
it shows that : for young age range income is low and range of income not height and thus understood , also income increase by age_range increase also range of income increase until reach to the age range more than 100 years old so we can pay attention to age range from 30and elder as income.
what is distribution of Customer age range?
customer age take the bell curve for the age range what is called normal distribution mean = median = mode. and this understood for age range
How many offer type per each offer status ?
it is appears that discount is the highest offer type all time, so we can keep offering discount as it highest among different categories
Future Improvements
- there are more potentials to solving many queries and it can be utilized to answer many posed questions related customer interaction based on the Age and income as a whole too.
- Try different additional machine learning models.







